Group Optimization for Multi-attribute Visual Embedding
1Shandong University 2University of Toronto 3University of Southern California, 4DNEG Visual Effects 5Tel Aviv University

Abstract
Understanding semantic similarity among images is the core of a wide range of computer graphics and computer vision applications.
However, the visual context of images is often ambiguous as images can be perceived with emphasis on different attributes.
In this paper, we present a method for learning the semantic visual similarity among images, inferring their latent attributes and embedding them into multi-spaces corresponding to each latent attribute.
We consider the multi-embedding problem as an optimization function that evaluates the embedded distances with respect to qualitative crowdsourced clusterings.
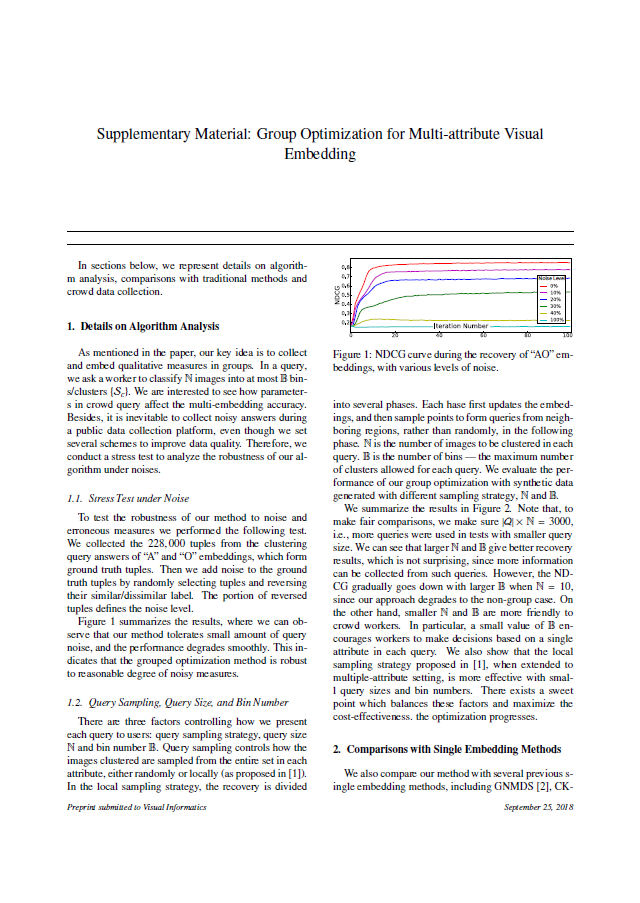
The key idea of our approach is to collect and embed qualitative pairwise tuples that share the same attributes in clusters.
To ensure similarity attribute sharing among multiple measures, image classification clusters are presented to, and solved by users. The collected image clusters are then converted into groups of tuples, which are fed into our group optimization algorithm that jointly infers the attribute similarity and multi-attribute embedding.
Our multi-attribute embedding allows retrieving similar objects in different attribute spaces.
Experimental results show that our approach outperforms state-of-the-art multi-embedding approaches on various datasets, and demonstrate the usage of the multi-attribute embedding in image retrieval application.
Results
Downloads



Acknowledgement
We thank the anonymous reviewers for their valuable comments. This study was funded by National Key Research \& Development Plan of China (No. 2016YFB1001404) and National Natural Science Foundation of China (No. 61602273).
BibTex
@article{ZENG2018,
title = "Group optimization for multi-attribute visual embedding",
journal = "Visual Informatics",
year = "2018",
issn = "2468-502X",
doi = "https://doi.org/10.1016/j.visinf.2018.09.004",
url = "http://www.sciencedirect.com/science/article/pii/S2468502X18300408",
author = "Qiong Zeng and Wenzheng Chen and Zhuo Han and Mingyi Shi and Yanir Kleiman and Daniel Cohen-Or and Baoquan Chen and Yangyan Li",
keywords = "Embedding, Semantic similarity, Visual retrieval"
}