第五届三维视觉国际会议(3DV2017)
时间:2017年10月10日-12日
地点:青岛
主页: http://3dv.org
会议简介
近年来,以三维视觉(3D Vision,下文简称3DV)为核心技术的行业不断涌现,市场潜力巨大,科研发展迅猛。3DV覆盖的专业领域包括但不仅限于三维获取、建模以及学习,面向诸如自动驾驶、医疗和机器人等领域应用。3DV 2016由斯坦福大学承办,吸引了逾500名专家学者参会,已经成为汇集三维视觉研究、原型系统、商业产品和人力资源的盛会。
3DV 2017由山东大学承办,大会主席为山东大学计算机学院和软件学院院长陈宝权教授。本届大会设立口头报告、短报告、特邀报告和海报展示等环节,为参会专家学者营造充分交流的理想平台。日程安排请见文章末尾,或浏览:http://irc.cs.sdu.edu.cn/3dv/program.html
3DV 2017录取学术论文73篇,代表了相关领域在三维重建、三维深度学习、运动捕捉、三维场景理解、SLAM等众多前沿科学问题的最新进展。
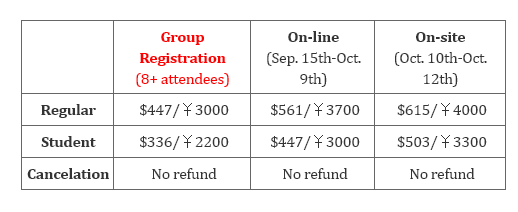
注册方式(新增团队注册)
注册链接:http://irc.cs.sdu.edu.cn/3dv/registration.html
10月9日前可以相对优惠的价格在我们的网站上进行在线注册(8人及以上团队注册更可享受8折优惠,团队优惠仅限在线注册时享受)。
注册即可参加3DV的所有会议环节,包括keynote, proceedings, coffee breaks和 banquet。详细会议日程请查看:http://irc.cs.sdu.edu.cn/3dv/program.html
团队注册流程:
参与团队注册的人员先各自单独从系统中注册,然后请其中一人将团队人员的注册邮箱发送给我们(3dv2017@gmail.com),在工作人员审核后会将优惠账单发送到名单上的所有邮箱中。
所有注册方式费用一览
特邀专家
本届3DV有幸邀请六位领域顶级专家做特邀报告,他们分别是:
高文
北京大学教授、院士、ACM/IEEE Fellow

报告主题:
Online visual processing for 3D reconstruction, SLAM, and object recognition
Niloy J. Mitra
伦敦大学学院教授,SIGGRAPH杰出青年学者奖获得者

报告主题:
Building a Factorized Scene Model: CapturingAppearance, Geometry, and Interactions
报告摘要:
Building realistic and accurate scene models of the world, both indoor andoutdoor, has long remained a central goal of shape analysis. While it is noweasy to capture large volumes of data including images, videos, scans,converting such data to a factorized representation with semantic annotationsremain a major challenge. For example, given an image, can we tell what are theobjects in the scene, how are they illuminated, or how will they functionallybehave in presence of external forces. Similar questions apply outdoors.
In this talk, I will discuss some of our recent attempts to factorize rawmeasurements into scene geometry, appearance, and their interactions. I willdiscuss how synthetically rendered images can be used to discover objectarrangements in photographs, capture real world illumination and texture usinggeometric proxies, and 'read off' physical object properties by observing themcollide in space. Our methods allow for large-scale unsupervised production ofrichly textured 3D models directly from image data, providing high-qualityrealistic objects for 3D scene design or photo editing applications, as well asa wealth of data for training machine learning algorithms for various inferencetasks in graphics and vision. For more details, data and code, pleasevisit: geometry.cs.ucl.ac.uk.
权龙
香港科技大学教授,IEEE Fellow

报告主题:
Computer Vision, Visual Learning, and 3D Reconstruction: Modeling the world with drones and smartphones!
报告摘要:
Professor Quan leads a computer vision team that uses photographs and deep visual learning technologies to produce complete 3D reconstruction of all types of locations and objects. In this talk, he reviews the developments in computer vision and visual learning over the past two decades. He also turns the focus on recent exciting work in deep visual learning and 3D reconstruction breakthrough in computer vision. Here, he showcases the approach using case studies of large-scale 3D reconstructions of hundreds of square kilometers high-rise metropolitan areas and undeveloped rural areas from drones, and small-scale daily objects from smartphones. He also demonstrates the online cloud platform and portal www.altizure.com with its crowd-sourced Altizure Earth, developed and funded by the HKUST team, rivaling the popular Google Earth!
Davide Scaramuzza
苏黎世联邦工学院机器人与视觉实验室主任

报告主题:
Robust, Visual-Inertial State Estimation: from Frame-based to Event-based Cameras
报告摘要:
I will present the main algorithms to achieve robust, 6-DOF, state estimation for mobile robots using passive sensing. Since cameras alone are not robust enough to high-speed motion and high-dynamic range scenes, I will describe how IMUs and event-based cameras can be fused with visual information to achieve higher accuracy and robustness. I will therefore dig into the topic of event-based cameras, which are revolutionary sensors with a latency of microseconds, a very high dynamic range, and a measurement update rate that is almost a million time faster than standard cameras. Finally, I will show concrete applications of these methods in autonomous navigation of vision-controlled drones.
杨睿刚
百度主任架构师,深度学习实验室(IDL)首席科学家

报告主题:
3D Vision Research and Applications at Baidu
报告摘要:
In the Inaugural AI Developer Conference “Baidu Create” on July 5th 2017, Baidu announced its all-in on AI policy. Among the AI-based open platforms announced during the conference, Appollo is for autonomous driving. I will talk about 3D vision’s crucial rule in the Appollo platform, in particular how 3D vision and deep learning can mutually benefit from each other’s advances. In addition, I will introduce 3D vision related research and productization in AR and robotics.
张正友
微软雷德蒙研究院首席研究员,ACM/IEEE Fellow

报告主题:
3D Computer Vision for ImmersiveInteraction and Remote Collaboration
报告摘要:
We look into human-computer interaction andhuman-human remote collaboration. In human-computer interaction, multitouchinteraction has become increasingly popular because touch input feels morenatural than the traditional keyboard and mouse. Consequently, there has beenrapid development of multitouch interactive display technologies. Thetraditional touch interaction, however, is not without its limitations. Onefundamental limitation is that the touch is “blind.” The system does not knowanything that happens off the board. We propose a system that augments touchinput with visual understanding of the user to improve interaction with a largetouch-sensitive display. A commodity color plus depth sensor such as MicrosoftKinect adds the visual modality and enables new interactions beyond touch.Through visual analysis, the system understands where the user is, who the useris, which hand the user is using, and what the user is doing even before theuser touches the display. Such information is used to enhance interaction inmultiple ways. In human-human remote collaboration, the existingvideoconferencing systems, whether they are available on desktop and mobiledevices or in dedicated conference rooms with built-in furniture and life-sizedhigh-definition video, leave a great deal to be desired: mutual gaze, 3D,motion parallax, spatial audio, to name a few. We propose an immersiveTelepresence system that aims at bringing immersive experience intotelecommunication so people across geographically distributed sites caninteract collaboratively as if they were face-to-face. Computer vision,graphics and acoustics are used in capturing and rendering 3D dynamicenvironments in order to create the illusion that the remote participants arein the same room. Over the years, Microsoft has been conducting research anddevelopment of novel technologies to improve users’ experience in multimodalinteraction and immersive telecommunications.
论文推介
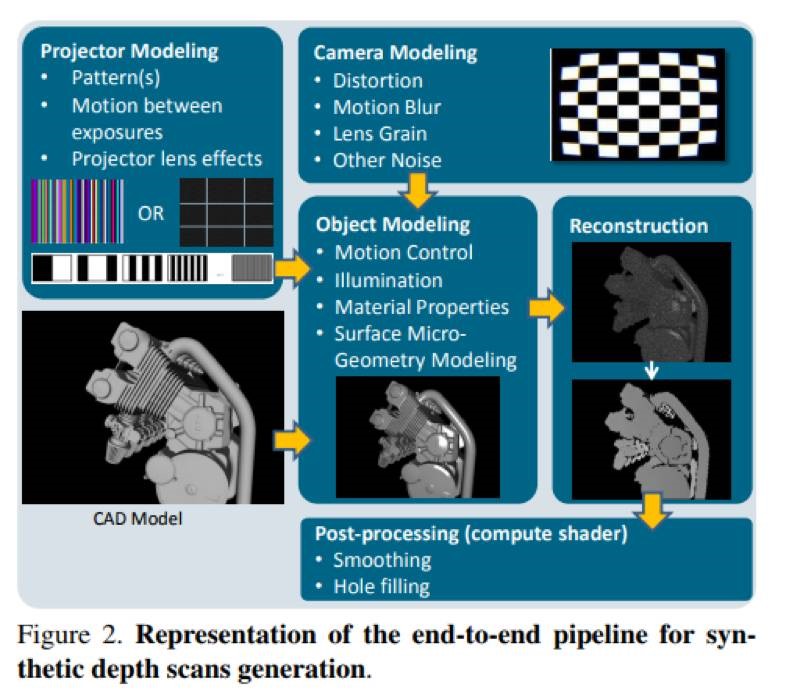
DepthSynth: Real-Time Realistic Synthetic Data Generation from CAD Modelsfor 2.5D Recognition
作者提出了一个具有创新性的完全端对端的框架DepthSynth,模拟这些设备的工作原理,通过建模一些关键的因素例如传感器噪声,材料反射率,表面几何信息等等,进而生成逼真的深度数据。
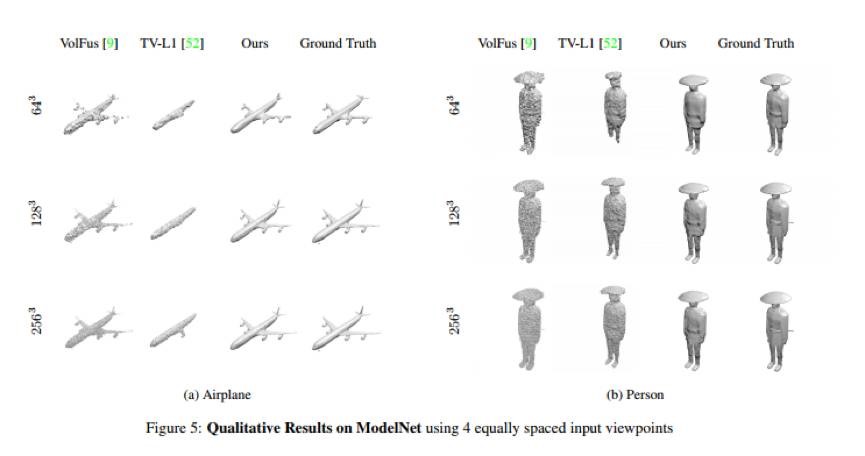
OctNetFusion: Learning Depth Fusion from Data
作者提出了一种利用深度学习的3DCNN框架OctNetFusion,依据输入的多视角深度图像,生成精确,完整的的3D重建结果。本文方法相比较之前的depth fusion的方法,能够有效处理遮挡的情况。利用合成的深度图像以及真实的kinect采集的数据,模型都可以产生引人注目的结果。
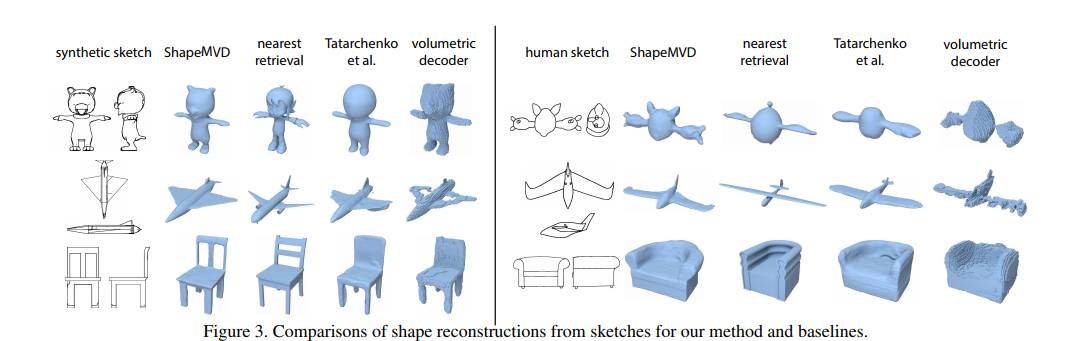
3D Shape Reconstruction from Sketches via Multi-view Convolutional Networks
这篇文章的工作非常有趣,作者设计了一个多视角的卷积神经网络,能够将sketches”立体化”,重建得到对应的3D形状。该神经网络可以将单视角或者多视角的素描图作为输入,然后得到密集的点云信息作为输出。
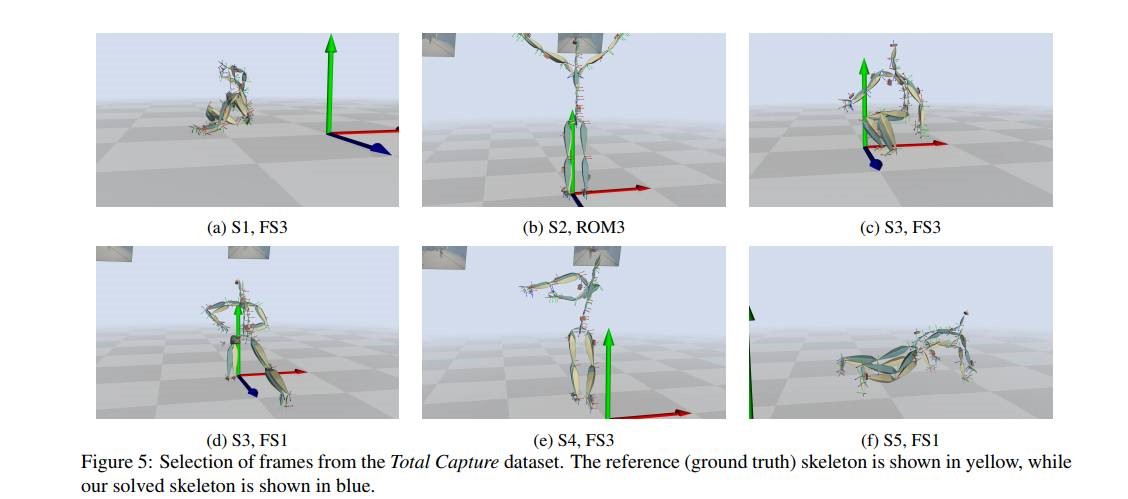
Real-time Full-Body Motion Capture from Video and IMUs
本文讲述了一个实时的动作捕捉系统,其结合了惯性测量单元(IMUS),相机信息以及一个先验的姿态模型,进而可以恢复完整的6个自由度的运动轨迹。实验部分也阐述了该系统在室内和户外均有较好的效果。
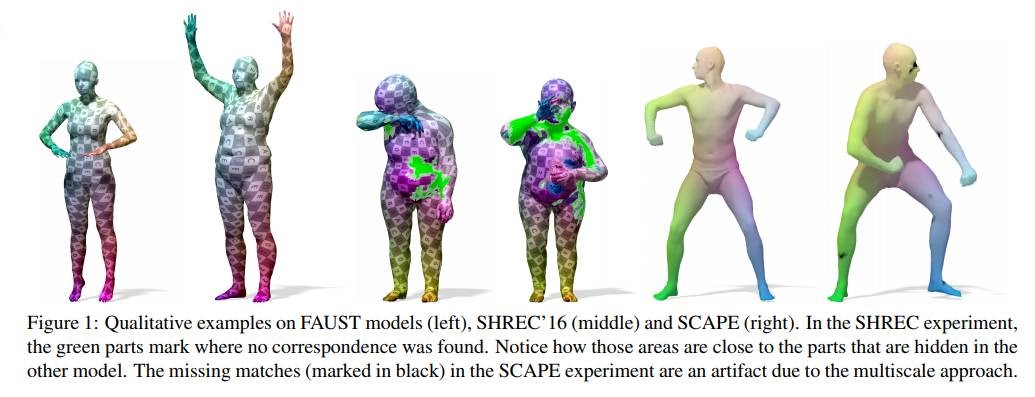
Efficient Deformable Shape Correspondence via Kernel Matching
文章提出了一种基于核函数匹配三维形状的方法,将三维的匹配问题转换成在点集合描述符之间的匹配,对遮挡等有挑战性的场景也有很好的效果。
更多精彩论文,请见: http://irc.cs.sdu.edu.cn/3dv/program.html
赞助商
感谢百度、光珀智能科技、纵目科技、商汤科技、阿丘科技、华为、银河水滴科技、图漾科技、先临三维科技、清影机器视觉技术、地平线、大势智慧科技、通甲优博等众多业界巨头和创业新星对本届大会的大力赞助。

3DV 2017诚挚邀请您的参与
让我们青岛见~
附:日程安排
2017年10月10日 星期二
9:00 - 9:15 AM Opening Remarks
9:15 - 10:00 AM Keynote 1: Zhengyou Zhang, "3D Computer Vision for Immersive Interaction and Remote Collaboration"
10:00 - 10:30 AM Coffee Break
10:30 - 11:10 AM Oral Session 1
11:10 - 11:30 AM Spotlight Session 1
11:30 - 12:30 PM Poster session 1
12:30 - 2:00 PM Lunch
2:00 - 2:45 PM Keynote 2: Davide Scaramuzza,"Robust, Visual-Inertial State Estimation: from Frame-based to Event-based Cameras"
2:45 - 3:10 PM Coffee Break
3:10 - 3:50 PM Oral Session 2
3:50 - 5:20 PM Forum: The challenges and opportunities in 3D sensing
5:20 - 6:20 PM Poster session 1
2017年10月11日 星期三
9:00 - 9:15 AM Announcements
9:15 - 10:00 AM Keynote 3: Wen Gao, Online visual processing for 3D reconstruction, SLAM, and object recognition
10:00 - 10:30 AM Coffee Break
10:30 - 11:10 AM Oral Session 3
11:10 - 11:30 AM Spotlight Session 2
11:30 - 12:30 PM Poster session 2
12:30 - 2:00 PM Lunch
2:00 - 2:45 PM Keynote 4: Long Quan, "Computer Vision, Visual Learning, and 3D Reconstruction: Modeling the world with drones and smartphones!"
2:45 - 3:10 PM Coffee Break
3:10 - 3:50 PM Oral Session 4
3:50 - 4:25 PM Spotlight Session 3
4:25 - 5:25 PM Poster session 2
5:30 - 8:00 PM Banquet
2017年10月12日 星期四
9:00 - 9:15 AM Announcements
9:15 - 10:00 AM Keynote 5: Niloy Mitra, "Building a Factorized Scene Model: Capturing Appearance, Geometry, and Interactions"
10:00 - 10:30 AM Coffee Break
10:30 - 11:10 AM Oral Session 5
11:10 - 11:30 AM Spotlight Session 4
11:30 - 12:30 PM Poster session 3
12:30 - 2:00 PM Lunch
2:00 - 2:45 PM Keynote 6: Ruigang Yang, "3D Vision Research and Applications at Baidu"
2:45 - 3:10 PM Coffee Break
3:10 - 3:50 PM Oral Session 6
3:50 - 4:20 PM Spotlight Session 5
4:20 - 5:20 PM Poster session 3
5:20 - 6:20 PM Awards, Closing Remarks and 3DV-18
更多详细日程请访问: http://irc.cs.sdu.edu.cn/3dv/program.html
