2017年10月12日上午9:00,3DV国际会议最后一天的日程正式开启。会议第三日的热度依然不减,两场特邀专家报告,来自斯坦福、牛津、清华等名校的口头报告和短报告,碰撞学术思想的海报展览,反映产业界趋势的企业展区,更有Best
Paper的颁奖仪式,以及为3DV 2017正式画上句号的闭幕式。3DV 2017已圆满落幕,回顾三天以来的会议,我们是否能够从其中窥见三维视觉的未来呢?
特邀专家报告
10日到12日会议期间,3DV主办方共邀请6位领域内顶级专家,每天都会有两场特邀专家报告。第三日的报告分别由伦敦大学学院教授,SIGGRAPH杰出青年学者奖获得者Niloy J.Mitra,和百度研究院三维视觉首席科学家杨睿刚老师带来。
Niloy
J.Mitra:Building a Factorized Scene
Model: CapturingAppearance, Geometry, and Interactions
Niloy
J.Mitra教授主要研究形状分析和几何处理方面的算法。在本次报告中Mitra教授给我们带来场景建模方面的工作介绍。Mitra教授首先展示了一张真实图片和一张难以分辨真假的真实感渲染图片,借此引出他们的工作,包括如何建出三维模型以及如何恢复材质纹理和光照。

难以区分的真实图与渲染图
他依据图片的数量多少和质量高低分为四种情况,详细讲解了每种情况下的处理方法,并展示了同一纹理贴到了各种椅子模型上的实验结果。最后Mitra教授介绍了他们在大规模结构化城市重建的工作。优于Google的街景重建工作,Mitra教授团队解决了建模中每个视角用的纹理集合不一样,没有根据法向渲染,没有结构细节等问题。随后展示了对一个伦敦街区的重建效果视频,在重建结果里可以清楚看到窗户等结构化信息。
城市建模可以用于城市规划和建筑设计,例如在设计一个新建筑时,如果有周边结构化的建模,就可以看到新建筑在此地与周边建筑的效果,并可以根据窗口位置,判断新建筑是否会影响到邻居隐私。除此之外,该工作为照片编辑等应用提供大量高度真实感的模型,也可以为图形和视觉方面的机器学习算法提供大量的训练数据。
伦敦街区的重建效果视频
杨睿刚:3D Vision Research and Applications at Baidu
杨睿刚老师首先介绍了百度的AI架构,通过百度AI开放平台下的自然语言处理、知识图谱、图片、视频等,构建了一个AI生态系统。他着重讲了百度的自动驾驶研究——Apollo项目。这是一个自动驾驶的开源平台。为我们介绍了项目架构:由云服务平台、开放软件平台、参考硬件平台和参考车辆平台构成。 其中环境探知技术的核心是利用传感器收集到的数据进行检测、场景理解与语义分割,最终预测和规划车辆的行驶路径。之后介绍了百度的高清晰度地图项目,这个是自动驾驶的基础。另外百度的激光雷达SLAM项目,包括特征提取、帧间匹配以及滑动窗口优化三步。
杨老师之后介绍了百度在机器人方面的工作。机器人的主要问题包括导航、地图绘制以及障碍物躲避三个方面。百度公开了其研发的机器人平台,其中的SDK实现了机器人相关的各种功能。杨老师又介绍了机器人平台的硬件传感模块、VIO、重定位、基于双目视觉的障碍物检测等内容。

最后是百度在其他领域的情况。百度的人脸识别准确率在99%以上,也可以检索到人年轻时的照片。杨老师展示了一个例子,输入杨老师的照片,度秘可以从杨老师大学毕业照里找到哪个是他,而在场的观众却很难分辨出来。最后杨老师总结了百度的无人驾驶,希望百度的无人驾驶早日驶入我们的真实世界!
口头报告&短报告&海报
第三日的论文部分同样精彩。本日的口头报告、短报告和海报环节汇聚了众多名校在三维视觉领域的最新研究成果:
SEGCloud: Semantic
Segmentation of 3D Point Clouds
来自斯坦福大学的Lyne P
Tchapmi等人在其工作中提出了一种新的端到端框架来获取像素级的3D分割。该方法融合了神经网络,三线性插值和全连接条件随机场的优点。在两个室内3D数据集和两个户外3D数据集上的实验结果表明,该方法的表现优于现有的各类方法。
Using
learning of speed to stabilize scale in monocular localization and mapping
来自牛津大学的研究员Duncan P Frost为大家带来了精彩的报告。现有的单视角地图创建与定位算法存在着尺度上的漂移,难以闭合的问题,导致最终的失败。本报告的研究人员,提出了一种矫正漂移的成像方法,使用卷积神经网络通过连续的单视角推断摄像机的速度。同时,本报告提出了用于捆绑调整时速度评估的正则优化器,避免了信息骤变的突发性陷阱。通过实验可看出,本报告提出的方法相比于现有方法可以获得更加准确的效果。
3D
Object Classification via Spherical Projections
清华大学的Zhangjie
Cao报告了一种分类三维物体的新方法——将三维物体投影到球形域上,利用神经网络对球形投影进行三维物体的分类。球面投影分类法结合了结合两种主流的三维分类方法的优势——即基于图片的方法和基于三维模型的方法,从而可以利用大量的图片数据集进行与训练,且球面投影法与基于体素的方法类似,能够编码完整的三维物体信息。
论文收录情况
闭幕式上,议程主席Sudipta
Sinha带我们回顾了3DV 2017的审稿历程,本次3DV国际会议共投稿171篇,经过将近七个星期的评审期,最终收入口头报告论文12篇、短报告25篇、海报36篇。
Best Paper 公布与颁奖
Best
Paper奖项包括Best Paper、Best
Student Paper和Best Paper Honorable Mention三项,由山东大学的李扬彦教授为大家颁奖。 究竟有哪些文章获此殊荣呢?让我们一起来看看吧。

Best
Paper:Learning Human Motion Models for Long-term
Predictions
Partha
Ghosh (ETH Zurich), Jie Song (ETH Zurich), Emre Aksan (ETH Zurich), Otmar
Hilliges (ETH Zurich)
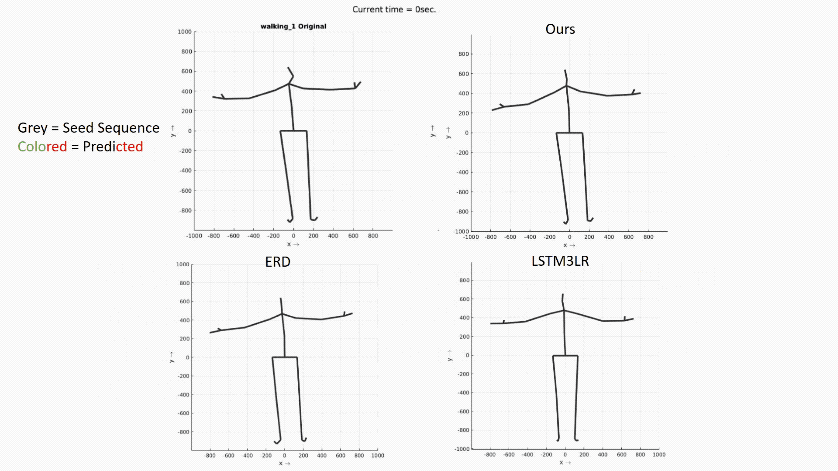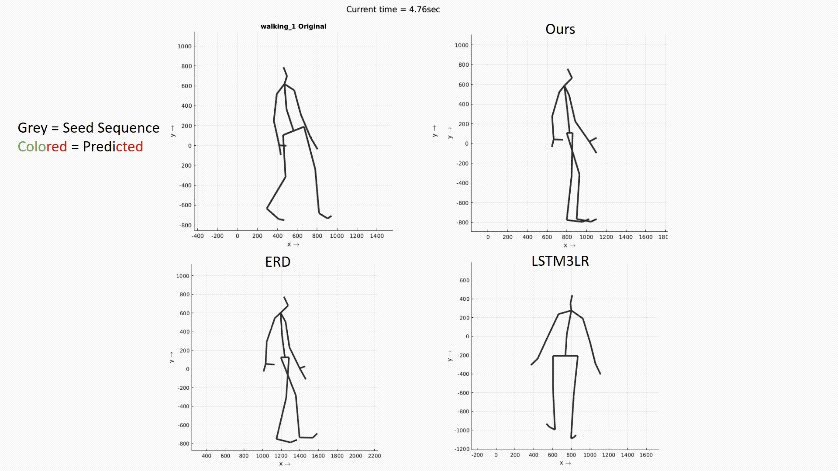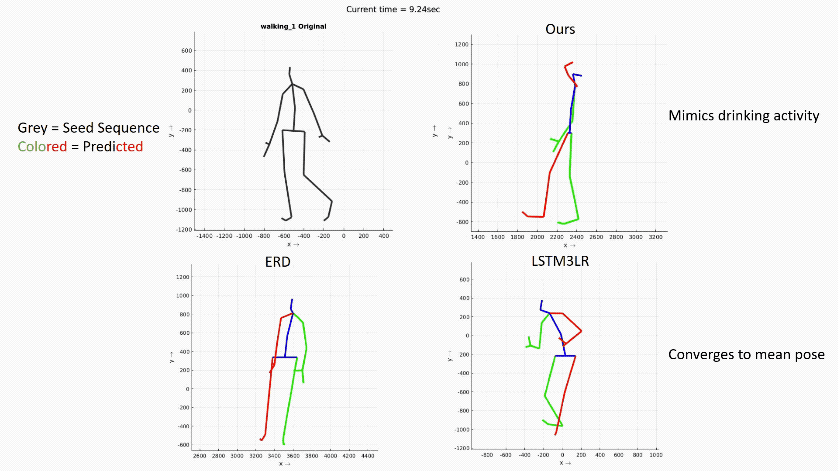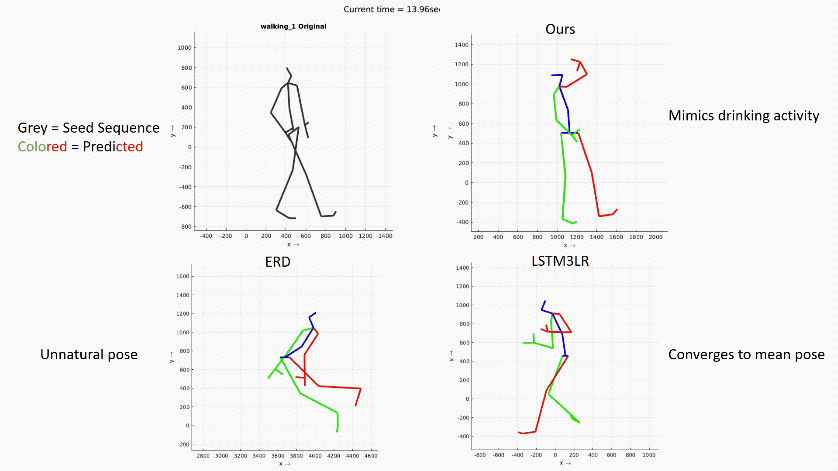
在长时间尺度上预测人的运动在各个应用领域仍然是一个很具挑战性的问题。在这个报告中,作者介绍了他们提出一个预测时空运动模型的新架构:Dropout
Autoencoder LSTM (DAE-LSTM) ,这个架构能够在长时间尺度上合成较为自然的运动序列,而不会出现灾难性的漂移或退化。据作者介绍,这个模型由两部分组成:一个三层循环神经网络(用于模拟临时方面)和一个新型的自动编码器(通过随机删除训练中关节的信息,对人体骨骼的空间结构进行隐性恢复)。此外作者还提出一种新的评估方案,使用动作分类器来评估合成运动序列的质量。通过报告中的展示,可以看出这项研究相比之前的方法有更好的表现。
Best
Student Paper:Sparsity
Invariant CNNs
Jonas
Uhrig (Daimler AG), Nick Schneider (Daimler AG), Lukas Schneider (Daimler),
Thomas Brox (Univ. of Freiburg), Andreas Geiger (Max Planck Institute)
传统的卷积网络在应用到稀疏数据时,由于缺失数据的位置所含信息也会被提供给网络,因此总在着表现不佳的问题。本报告的研究人员为了解决这个问题,提出了一个简单而有效的稀疏卷积层,它明确地考虑了卷积运算期间丢失数据的位置。在各种基线方法的合成和实际实验中,他们提出的网络架构有着显著的优点。它明确地考虑了卷积过程中缺失数据的位置。与具有稠密基线的网络相比,研究人员所提出的稀疏卷积网络能够很好地推广应用到新的数据集,并且与数据稀疏程度保持不变。研究人员通过KITTI基准数据得到了全新的数据集,得到了包含93K深度信息的RGB图像。他们的数据集可以在现实环境中进行深度上升采样和深度预测的训练和评估,并在出版后提供。该项工作,无疑是机器学习应用于计算机视觉和图形学领域的又一大创新。

Best
Paper Honorable Mention:Fast
Incremental Bundle Adjustment with Covariance Recover
Viorela
Ila (ANU), Lukas Polok (Brno Univ. of Technology), Marek Solony (VUT), Klemen
Istenic (UDG)
现有的获得环境稀疏三维表示的算法中,常通过捆绑调整(Bundle Adjustment,BA)和运动恢复结构(Structure
From Motion, SFM)技术来评估相机位置与稀疏点集生成。随着科技发展,越来越多的应用在三维重建技术的在线性与实时性两个方面提出了更高的要求。此外,也需要通过重建质量检测与反馈机制选择最优视角,同时保证收集数据的大小合理。本报告中,作者提出了一种新颖有效的方法,解决相关的非线性体统的问题,求得最优解,增加了用于长轨迹相机应用的增量式BA求解器效率,并提供了协方差恢复机制。在实时三维重建领域做出了重大贡献。
产业界中的三维视觉
本次3DV
2017国际会议吸引了众多业界巨头和创业新星的赞助与参展,我们也可从其中看到产业界的目前发展状况。
先临三维带来了一款消费级的EinScan-Pro+多功能手持式3D扫描仪,用于检测获取三维图像信息,手持式3D扫描仪获取的数据更为通用,可以应用到三维重建、逆向设计、三维打印等方面。
大势智慧带来的建模师的分享平台(Get3D)在本次会议上首次亮相,在该平台上,设计人员只需通过实物拍摄,上传照片和生成模型三步便能完成在线建模,从而降低建模的技术门槛。
地平线演示了其ADAS系统的使用效果。将ADAS系统安装在车辆上,能够实时的采集到一些市区道路的数据,其中包括机动车的车头车尾、行人和车道线等,检测中几乎不存在漏检和误检的情况。
图漾公司的三维深度传感器在传统双目视觉基础上配以红外结构光辅助投影,能够获取更多的景深细节,同时对外界环境光具备更灵活的适应性。
3DV也成为了企业招贤纳士的一个平台。华为公司除了展示基于图像的3D人脸和人体重建技术的研究成果外,华为媒体技术实验室在会上积极招募智能音频、3D视觉和图形图像等方向的人才。通甲优博在会上也积极招募深度学习算法工程师,VSLAM算法工程师、立体视觉算法工程师和算法优化工程师等职位。


回顾与未来
三天的3DV落下帷幕,闭幕式的最后,大会主席陈宝权老师感谢所有参会者的到来,希望大家可以享受在青岛的美好时光。
陈老师用一个视频带我们回顾了会议期间的特邀报告、口头报告、短报告、海报、欢迎会和晚宴的精彩瞬间,还有来自山东大学交叉研究中心的志愿者们为会议服务的身影。
3DV
2017已落幕,那么未来呢?3DV 2018将在美丽的意大利城市维罗纳(Verona)举办,会议时间是2018年9月15号到2018年9月18号,会议论文接收截止到2018年6月5日,
感谢雷锋网记者协助报道。
